
 As an engineer, I know how hard it is to make things simple. I also know that any great solution must begin with a customer-focused mindset, and not one that creates technology for technology's sake.
As an engineer, I know how hard it is to make things simple. I also know that any great solution must begin with a customer-focused mindset, and not one that creates technology for technology's sake.
At Avi Networks, we’re distinguishing our solutions with a single-minded focus on making things intuitively obvious. If that means adding a few extra weeks to the design cycle to make life easier for the user, we’ll do it. And every idea and conversation here begins by “walking in our customers’ shoes” because it’s essential that we truly understand their needs so we can invent new approaches that guarantee the best customer experience.
I’d like to share with you four stories that give you a glimpse into our thought process, design challenges and engineering priorities as we set out to create the industry’s first cloud application delivery platform.
1. UNDERSTANDING CLOUD APPLICATION DELIVERY
When we first got together two years ago, we were keenly aware of the limitations of current solutions, which were plagued by complexity and unpredictable user experiences. They were also unable to adapt to the new world characterized by dynamic, mobile cloud environments. Our architectural goal was to create an application delivery solution that was uniquely suited for use across Enterprise IT and Private/Public Clouds. We wanted a solution that was highly scalable, achieved a much higher level of ease-of-use than any existing solution, and guaranteed the end-user application experience.
Current appliance-based designs have limited scalability because you can only scale up. In other words, to achieve higher scale, you need to keep adding devices, which forces you to manage multiple, discrete devices. This adds complexity and overhead.
Device-centric solutions also pose network design challenges because application traffic needs to be engineered to flow to the “service appliance.” This complicates network design and is often a network planning nightmare.
The increase in infrastructure complexity, compounded by unpredictable user demand, makes it challenging to provide a prescriptive set of options that will guarantee a positive end user experience. This constantly changing nature of today’s environments mandates a design imperative that the application delivery solutions be intelligent and self-correcting.
2. HYDRA
Our key realization was that a device-centric approach simply would not work. Instead, a revolutionary architecture was required, one that addresses the need to scale dynamically, improves ease of use, and fundamentally simplifies admin operations. This led to the development of our innovative architecture HYDRA™, or Hyperscale Distributed Resources Architecture.
HYDRA is based on the design principle of a logically centralized control with a distributed data plane. We learned that other industry experts had already been converging on such an approach – Google Andromeda, for one – which further validated the direction we were taking.
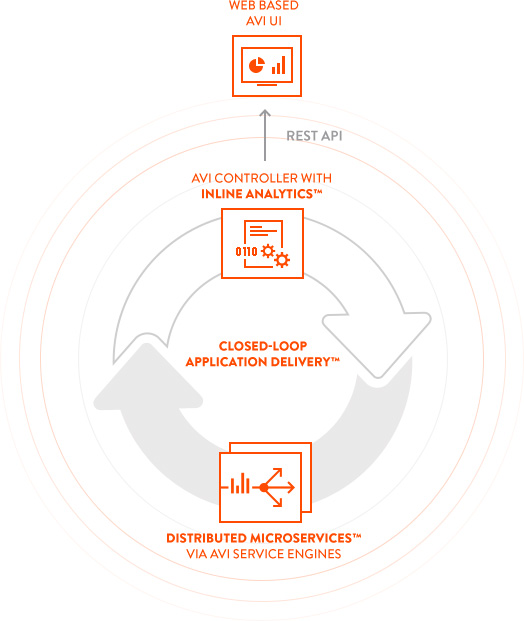
Here’s where our “secret sauce” comes into play. HYDRA decomposes a service appliance into functional components, where the data plane is modeled as Distributed Microservices and control plane elements are integrated into a centralized controller.
The data plane, now reduced to a compact and efficient entity, is distributed and co-located alongside the applications, thereby eliminating network design or planning challenges and enabling scalable network services.
The control plane is centralized and is supported by REST-based programmable APIs that are capable of dynamic service creation. This centralized model gives customers a single point of integration, automation, and programmability, making it much easier to manage.
What does this mean? Customers can now use HYDRA to scale each application delivery microservice independently – particularly important as applications move among various cloud locations. This allows customers to create a single, infinitely scalable Application Delivery Platform without adding complexity.
3. INLINE ANALYTICS
At this point, we now had a very scalable, simple-to-manage architecture, but that wasn’t enough. In order to maximize application performance and ensure the user experience, we knew we had to integrate visibility and analytics – this is known as our Inline Analytics™.
While customers today use multiple tools to monitor users, applications, servers, the network, ADCs, and more, these are each discrete threads of information that lack an integrated, holistic perspective.
So we built upon our distributed microservices and added an Inline Analytics™ subsystem. It features a highly-optimized, sharded data-store that continuously collects telemetry data about the application, end-user, and Application Delivery Service from our Distributed Microservices, as well as infrastructure telemetry data, for a fully unified view. The system analyzes in real-time and correlates the various data to provide actionable insights.
Our Indexer Engine supports highly efficient natural language search and our Analytics & Anomaly Engine uses machine learning and multiple anomaly detection algorithms to process telemetry data and produce both insights and recommendations.
For example, let’s say that the average number of requests on a Monday is 5,000 per second, but one Monday, that number spikes to 20,000 per second. The Inline Analytics module flags that anomaly and asks the user whether this is an expected event or not. If the spike was anticipated, the Inline Analytics module automatically provides proactive recommendations to the IT administrator to take necessary remedial action.
4. CLOSED-LOOP APPLICATION DELIVERY
We were almost there with a scalable, robust architecture and built-in visibility and analytics engine. Our final step was to connect the two to come up with the first Closed-Loop Application Delivery™ solution that’s not only scalable and “aware,” but intelligent enough to automate certain tasks so they’re done faster and more efficiently.
Think of our Closed-Loop Application Delivery solution like the popular Nest learning thermostat: save money and time by using a “smart” tool that’s aware of all your activities, learns user and application patterns to program itself, and is dynamically making adjustments in real-time to optimize the end user experience - all without any human intervention.
When we first began, the difficult problem of application delivery in the cloud wasn’t an issue for hyperscale cloud companies because they had the means to dedicate teams of people and buckets of dollars towards developing a custom solution in-house. But that wasn’t a viable option for most enterprises.
Today, all that’s changed.

